← Back to projects 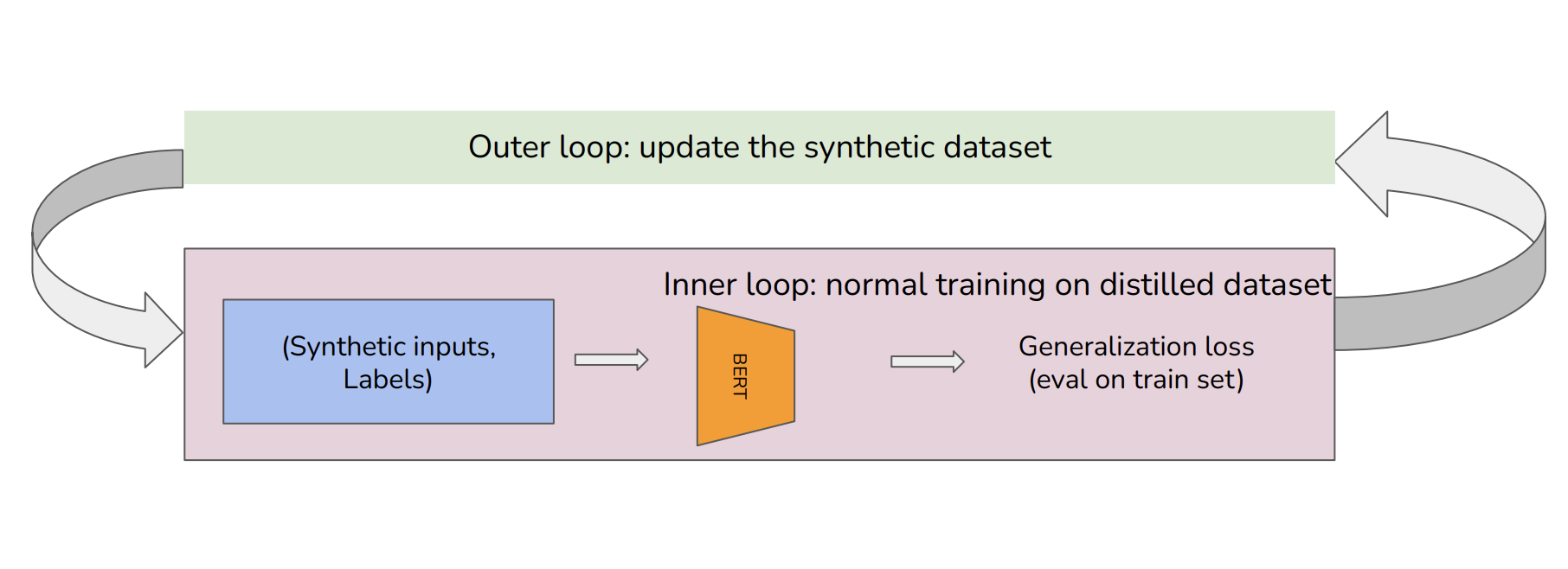
Dataset Distillation for LLMs
COS 597G: Understanding Large Language Models @ Princeton University
Training large language models on datasets like Common Crawl (541TB) is computationally infeasible in many settings. We explore distilling large-scale textual data as a solution. While vision-community approaches may be ineffective for LLMs, this work motivates investigations into the minimum information required to train performative LLMs and the compositionality of compact linguistic knowledge.