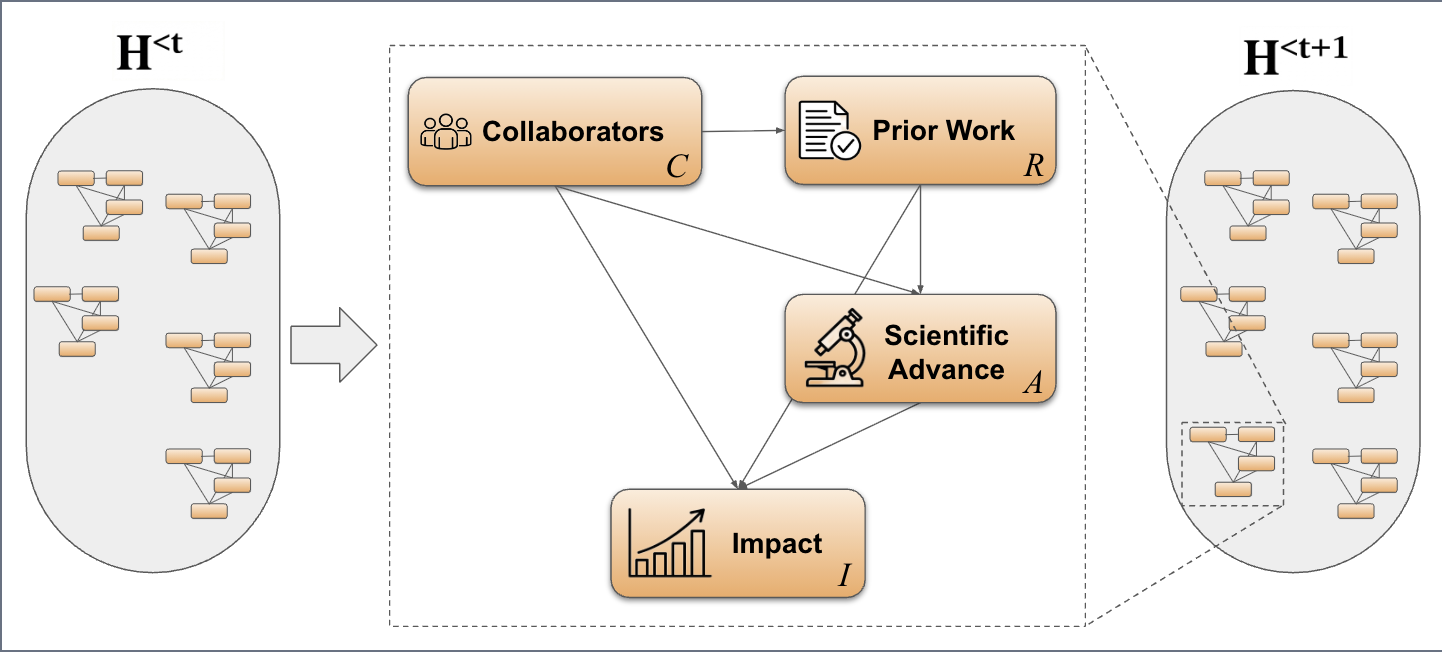
PreScience: A Benchmark for Forecasting Scientific Contributions Anirudh Ajith, Amanpreet Singh, Jay DeYoung, Nadav Kunievsky, Austin C. Kozlowski, Oyvind Tafjord, James Evans, Daniel S. Weld, Tom Hope, Doug Downey Preprint 2026 arXiv Code
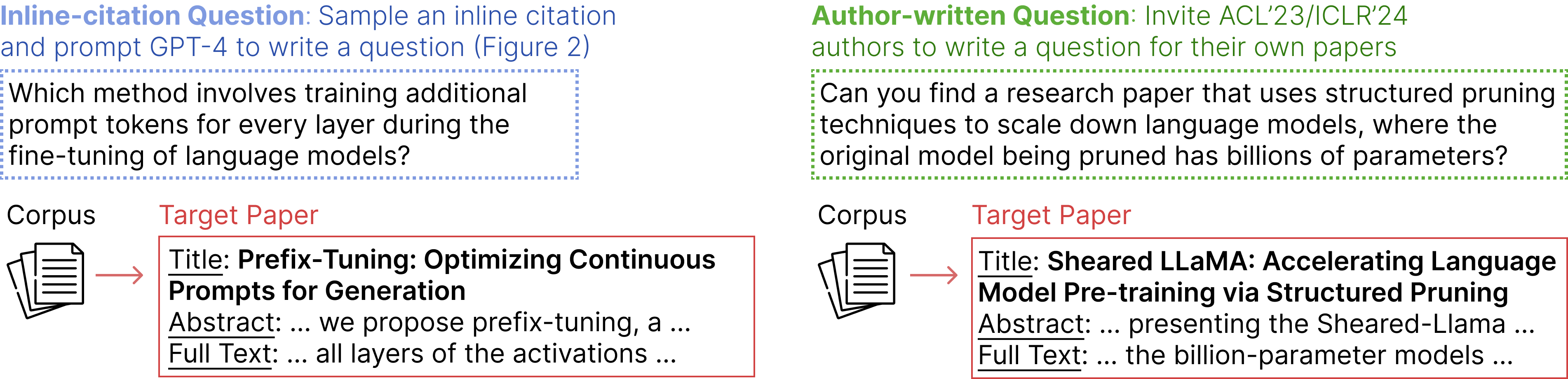
LitSearch: A Retrieval Benchmark for Scientific Literature Search Anirudh Ajith, Mengzhou Xia, Alexis Chevalier, Tanya Goyal, Danqi Chen, Tianyu Gao EMNLP 2024 Paper Code
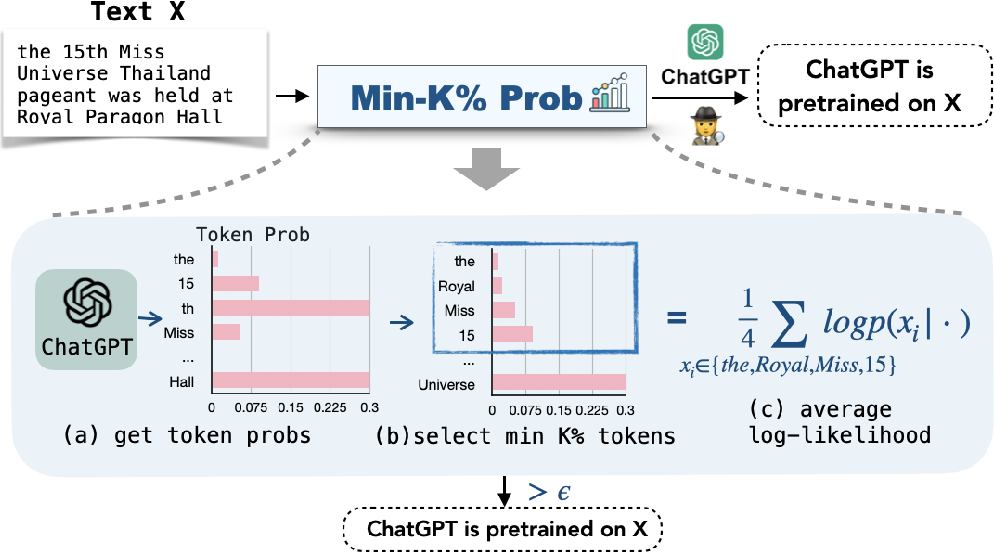
Detecting Pretraining Data from Large Language Models Weijia Shi*, Anirudh Ajith*, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, Luke Zettlemoyer ICLR 2024 Paper Code
Downstream Trade-offs of a Family of Text Watermarks Anirudh Ajith, Sameer Singh, Danish Pruthi EMNLP Findings 2024 Paper Code
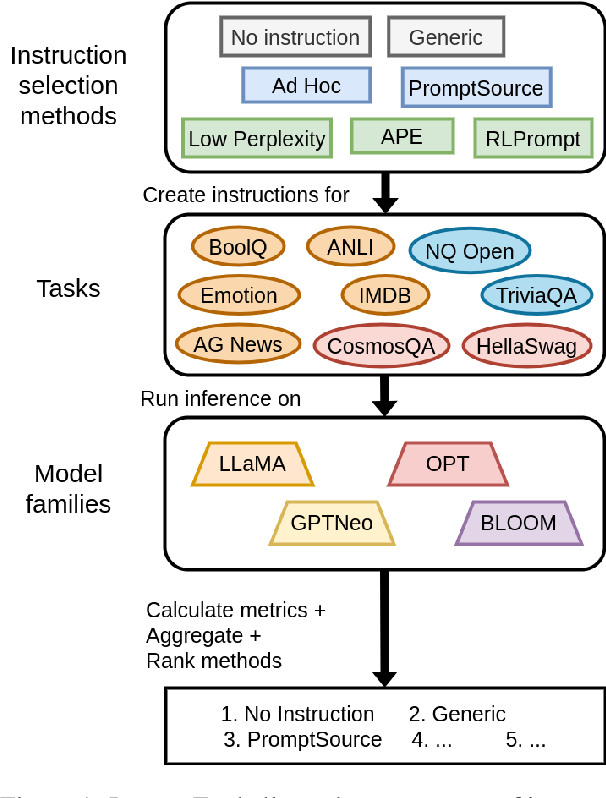
InstructEval: Systematic Evaluation of Instruction Selection Methods Anirudh Ajith, Chris Pan, Mengzhou Xia, Ameet Deshpande, Karthik Narasimhan NAACL Findings 2024 Paper Code
Adapting Language Models to Compress Contexts Alexis Chevalier, Alexander Wettig, Anirudh Ajith, Danqi Chen EMNLP 2023 Paper Code